

Sprachmodelle#
Modell-Auswahl#
Bei Assistenten und Arbeitsabläufen kannst du auswählen, welches Sprachmodell (LLM) du für die Aufgabe nutzen möchtest. Welche Modelle angezeigt werden, hängt davon ab, was dein Administrator gebucht hat. Die AI-Tools unterstützen zur Zeit die Modelle von OpenAI/Azure, Anthropic, Google, Mistral und Perplexity.
Außerdem kannst du KI-Modelle hinzufügen, die von Anbietern in Europa bereitgestellt werden. Zum Beispiel die offenen Modelle GPT-OSS und Qwen bei OVHcloud in Frankreich. Damit kannst du Aufgaben datenschutzkonform in Europa erledigen, ohne dass die Daten in die USA oder andere Regionen übertragen werden müssen.
Weitere offene Modelle wie DeepSeek, Kimi oder GLM stellen wir über die Infrastruktur von Microsoft und Fireworks AI bereit. Diese verarbeiten Anfragen auch auf Servern außerhalb Europas.
In der Modell-Card ist immer angegeben, wo die Server stehen.
Modell-Eigenschaften#
Nicht alle Modelle können die Werkzeuge wie „Webseiten besuchen“ oder „Charts erzeugen“ verwenden. Einige Modelle können hochgeladene Bilder verarbeiten und zum Beispiel Texte extrahieren.
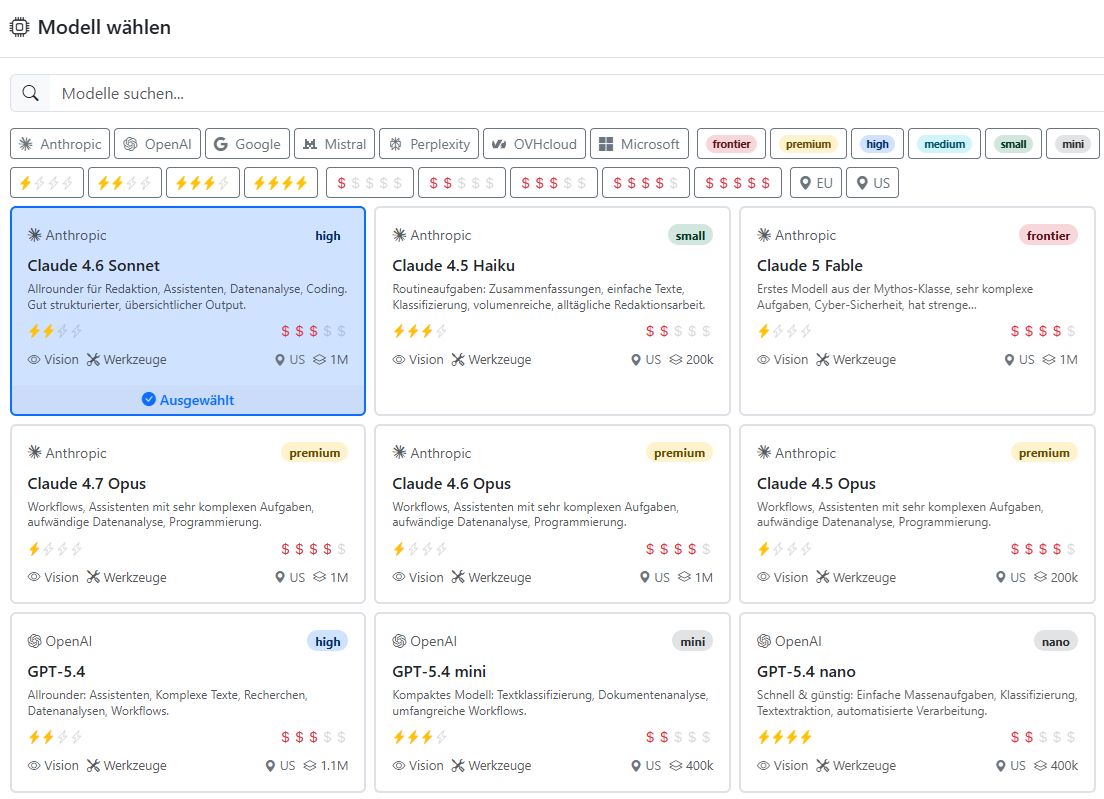
Damit du alle Fähigkeiten und Eigenschaften der Modelle auf einen Blick hast, findest du in der Modell-Auswahl zu jedem Modell eine detaillierte Modell-Karte.
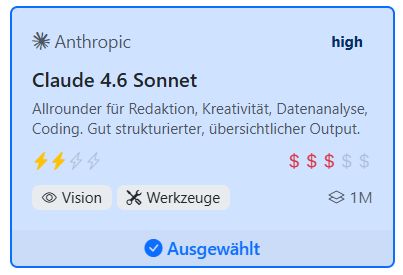
Die Karte zeigt den KI-Anbieter und den Namen des Modells mit einer kurzen Beschreibung. Die Symbole auf der Karte haben folgende Bedeutung:
Leistungsklasse#

Damit du die Modelle verschiedener Anbieter besser vergleichen kannst, haben wir sie in Leistungsklassen eingeteilt. Die Leistungsklassen sind absteigend sortiert von frontier (Flagschiff-Modelle, sehr teuer und langsam) bis nano (für einfache Aufgaben, schnell, günstig):
frontier, premium, high, medium, small, mini, nano.
Für die meisten Redaktions-Aufgaben sind die Modelle der Leistungsklasse high völlig ausreichend.
Für einfache Aufgaben, die sehr oft ausgeführt werden, sind die Modelle der Leistungsklassen medium bis nano die beste Wahl. Nutze ein mini-Modell etwa, um einem Text Schlagworte zuzuordnen oder die Stimmung in einem Social Media Posting zu kategorisieren.
premium-Modelle brauchst du nur für sehr komplexe Analysen oder für Assistenten, die viele Werkzeuge verwenden oder andere Assistenten orchestrieren. Oder in der Software-Entwicklung für die Planung und Überarbeitung von Code.
Geschwindigkeit#

Die gelben Blitze auf der Modell-Karte geben die Geschwindigkeit eines Modells an. Je mehr Blitze, desto schneller ist das Modell.
Wir haben die Geschwindigkeit der Modelle in ein bis vier Blitze eingeteilt.
Kosten#

Die Kosten eines Modells hängen von seiner Leistungsfähigkeit ab. frontier-Modelle sind die teuersten, gefolgt von premium- und high-Modellen.
Je mehr Dollar-Zeichen auf der Modell-Karte, desto teurer ist das Modell. Die Modelle sind in ein bis fünf Dollar-Zeichen eingeteilt.
Score |
Zeichen |
Output-Preis / 1M Tokens |
|---|---|---|
1 |
$ |
< $1 |
2 |
$$ |
$1 - $6 |
3 |
$$$ |
$6 - $20 |
4 |
$$$$ |
$20 - $60 |
5 |
$$$$$ |
> $60 |
KI-Provider geben ihre Kosten üblicherweise pro einer Million Tokens an. Dabei sind die Ausgabe-Tokens in der Regel deutlich teurer als die Eingabe-Tokens.
Aber auch ein medium-Modell kann hohe Kosten verursachen, wenn du es in einem sehr langen Chat verwendest.
Beachte: Jedesmal, wenn du eine Nachricht in einem Chat sendest, wird der gesamte Chat (also alle vorherigen Nachrichten) als Eingabe an die KI gesendet. Hast du also einen langen Chat oder im Chat sind lange PDF-Dateien oder Analyse-Daten erhalten, dann steigt die Anzahl der verbrauchten Tokens schnell an. Einmal Enter drücken, kann dann schon mal 10 Euro oder mehr kosten.
Kontext-Fenster#
Das Kontext-Fenster gibt an, wie viele Tokens das Modell gleichzeitig verarbeiten kann. In der Modell-Karte findest du den Wert unten rechts: 1 M, 400 k, 128 k…
Aktuelle KI-Modelle haben meist ein Kontext-Fenster von einer Million Tokens (1M). Das sind etwa 750.000 Wörter oder 3.000 Seiten Text. Studien zeigen aber, dass schon bis zu 40% gefüllte Kontext-Fenster zu einem deutlichen Leistungsabfall führen können.
Tipp
Mache deine Chats nicht zu lang. Verwende nicht immer wieder den gleichen Chat aus dem Verlauf, sondern starte lieber einen neuen Chat.
Wenn du dennoch den Kontext aus einem vorherigen Chat benötigst:
Lass dir vom Assistenten die wichtigsten Informationen aus dem vorherigen Chat zusammenfassen und kopiere sie in einen neuen Chat. Die Ergebnisse sind dann oft besser, der Chat läuft schneller und die Kosten sind deutlich geringer.
Modelle suchen und filtern#
In der Modell-Auswahl siehst du oben ein Suchfeld. Dort kannst du den Namen eines Modells eingeben, um es schnell zu finden. Oder du gibst einen Begriff ein, der in der Beschreibung eines Modells vorkommt, zum Beispiel „Texte“ oder „Analyse“.

Unter dem Suchfeld sind die Filter. Damit kannst du die Modelle nach ihren Eigenschaften filtern, zum Beispiel nur Modelle aus der Leistungsklasse medium anzeigen; Modelle eines Anbieters oder einer Geschwindigkeitsklasse.
Modell-Übersicht#
Die folgenden Tabellen geben eine Übersicht aller unterstützten Modelle und ihrer Fähigkeiten.
Bemerkung
Vision - Das Modell kann hochgeladene Bilder verarbeiten (z. B. Text aus Bildern extrahieren).
Tools - Das Modell kann Werkzeuge wie „Webseiten besuchen“ oder „Charts erzeugen“ verwenden.
Denken - Das Modell verfügt über erweitertes Nachdenken (Reasoning): Es denkt vor der Antwort intern über die Aufgabe nach.
Wissen - Das Modell enthält Informationen bis zum angegebenen Datum.
✓ = verfügbar
OpenAI#
Modell |
Beschreibung |
Vision |
Tools |
Denken |
Wissen |
|---|---|---|---|---|---|
GPT-5.5 (Premium, Agenten, teuer) |
Premium-Modell für komplexe Aufgaben, Analysen und Software-Entwicklung. Kontext: 1 Mio. Token. |
✓ |
✓ |
✓ |
Dez. 2025 |
GPT-5.4 (Code, Agenten, komplexe Aufgaben) |
Sehr gut für komplexe Aufgaben, Analysen und Software-Entwicklung. Kontext: 1 Mio. Token. |
✓ |
✓ |
✓ |
Aug. 2025 |
GPT-5.2 (Code, Agenten) |
Verbesserte Version von GPT-5.1. Sehr gut für komplexe Aufgaben und Software-Entwicklung. Benötigt exakte Prompts. |
✓ |
✓ |
✓ |
Aug. 2025 |
GPT-5.1 (Code, Agenten) |
Stärkstes OpenAI-Modell der 5.x-Reihe. Sehr gut für komplexe Aufgaben und Software-Entwicklung. Benötigt exakte Prompts. |
✓ |
✓ |
✓ |
Okt. 2024 |
GPT-5 (Texte, Code) |
Starkes Modell. Schaltet intern bei Bedarf starkes Nachdenken ein. Kontext: 400.000 Token. Preise wie GPT-4 Omni. |
✓ |
✓ |
✓ |
Okt. 2024 |
GPT-5 Chat (Texte, VERALTET) |
Kann keine Tools verwenden. Kontext: 400.000 Token. |
✓ |
Sep. 2024 |
||
GPT-5 mini (Texte) |
Schnelle Version von GPT-5. Kontext: 400.000 Token. |
✓ |
✓ |
✓ |
Mai 2024 |
GPT-5 nano (Texte) |
Sehr schnell und günstig. Kontext: 400.000 Token. |
✓ |
✓ |
✓ |
Mai 2024 |
GPT-4.1 (Texte) |
Sehr großes Kontext-Fenster: 1 Mio. Token. 20 % günstiger als GPT-4 Omni. |
✓ |
✓ |
Jun. 2024 |
|
GPT-4 Omni (Texte, VERALTET) |
Leistungsfähiges Modell für professionelle Anwendungen. |
✓ |
✓ |
Okt. 2023 |
|
GPT-4 Omni Search (Recherche, VERALTET) |
GPT-4 Omni mit automatischer Internetsuche bei jedem Aufruf. Kann keine Tools verwenden. |
Okt. 2023 |
|||
GPT-4 Omni mini |
Schnell - der kleine Bruder von GPT-4 Omni. |
✓ |
✓ |
Okt. 2023 |
|
o3 mini (VERALTET) |
Kleines Reasoning-Modell mit erweitertem Nachdenken. Sehr schnell. Halb so teuer wie GPT-4 Omni. |
✓ |
✓ |
Okt. 2023 |
|
o1 mini (VERALTET) |
Optimiert für Deep Reasoning. Geeignet für komplexe Planungsaufgaben. Kann keine Tools verwenden. |
✓ |
Okt. 2023 |
Anthropic#
Alle Anthropic-Modelle haben eine integrierte Internetsuche.
Modell |
Beschreibung |
Vision |
Tools |
Denken |
Wissen |
|---|---|---|---|---|---|
Claude Opus 4.8 (komplexe Aufgaben, Agenten, Programmieren, teuer) |
Für komplexe Arbeitsabläufe, Agenten und Software-Entwicklung. |
✓ |
✓ |
✓ |
Jan. 2026 |
Claude Opus 4.7 (komplexe Aufgaben, Agenten, Programmieren, teuer) |
Für komplexe Arbeitsabläufe, Agenten und Software-Entwicklung. Verbraucht bis zu 40 % mehr Tokens als Opus 4.6. Die Einstellung Temperatur wird ab diesem Modell nicht mehr unterstützt. |
✓ |
✓ |
✓ |
Jan. 2026 |
Claude Opus 4.6 (komplexe Aufgaben, Agenten, Programmieren) |
Für komplexe Arbeitsabläufe, Agenten und Software-Entwicklung. |
✓ |
✓ |
✓ |
Mai 2025 |
Claude Opus 4.5 (komplexe Aufgaben, Agenten) |
Für komplexe Arbeitsabläufe und Agenten. Token-Preise knapp doppelt so hoch wie bei Claude Sonnet 4.5. |
✓ |
✓ |
✓ |
Mai 2025 |
Claude Sonnet 4.6 (Texte, Code) |
Starkes Anthropic-Modell. Sehr gut für Code-Erstellung und Texte. Befolgt sehr gut Anweisungen. |
✓ |
✓ |
✓ |
Mai 2025 |
Claude Sonnet 4.5 (Reports, Code, Agenten) |
Starkes Anthropic-Modell. Sehr gut für Code-Erstellung und Texte. |
✓ |
✓ |
✓ |
Jan. 2025 |
Claude Haiku 4.5 (schnell, günstig) |
Kleines und schnelles Modell. Erreicht fast das Niveau von Claude Sonnet 4. |
✓ |
✓ |
✓ |
Feb. 2025 |
Claude Sonnet 4 (Texte, Reports, Code) |
Gut für Code-Erstellung und Texte. |
✓ |
✓ |
✓ |
Okt. 2024 |
Google#
Mit den Gemini-Modellen von Google kann die Google KI-Suche genutzt werden. Alle Modelle können Eingabe-Bilder erkennen und verarbeiten.
Modell |
Beschreibung |
Vision |
Tools |
Denken |
Wissen |
|---|---|---|---|---|---|
Gemini 3.1 Pro (Texte, Denken, Code) |
Stärkstes Google-Modell. Komplexes Denken, kreatives Schreiben, Recherche, Agenten, Datenanalyse, Programmieren. Bis 1 Mio. Input Token. |
✓ |
✓ |
✓ |
Jan. 2025 |
Gemini 3.5 Flash (Texte, Denken, Code) |
Starker Allrounder: Zusammenfassungen, Dokumentenanalysen, täglicher Redaktions-Workflow, Agenten, Datenanalyse, Programmieren. Bis 1 Mio. Input Token. |
✓ |
✓ |
✓ |
Jan. 2026 |
Gemini 3.1 Flash Lite (Texte, schnell, günstig) |
Schnelles und günstiges Modell. Schreiben, einfache Agenten. Bis 1 Mio. Input Token. |
✓ |
✓ |
✓ |
Jan. 2025 |
Gemini 2.5 Pro (Texte, Denken, Code) |
Verbessertes Denken und Schlussfolgern, multimodales Verständnis, erweitertes Programmieren. Bis 1 Mio. Input Token. |
✓ |
✓ |
✓ |
Jan. 2025 |
Gemini 2.5 Flash (Texte, günstig) |
Starkes und schnelles Reasoning-Modell. Bis 1 Mio. Input Token. |
✓ |
✓ |
✓ |
Jan. 2025 |
Gemini 2.5 Flash Lite (sehr schnell, günstig) |
Sehr schnelles und günstiges Modell für einfache Aufgaben. Bis 1 Mio. Input Token. |
✓ |
✓ |
✓ |
Jan. 2025 |
Mistral#
Die Modelle der französischen Firma Mistral AI mit Servern in Europa.
Modell |
Beschreibung |
Vision |
Tools |
Denken |
Wissen |
|---|---|---|---|---|---|
Mistral Large (Texte, Agenten) |
Stärkstes Mistral-Modell für Texte und komplexe Aufgaben. 256k Token Kontext. |
✓ |
✓ |
✓ |
Dezember 2025 |
Mistral Medium (Texte) |
Mittleres Modell für die Generierung von Texten. 256k Token Kontext. |
✓ |
✓ |
✓ |
Mitte 2025 |
Mistral Small |
Klein und schnell. 256k Token Kontext. |
✓ |
✓ |
✓ |
Juni 2025 |
Codestral (Programmieren) |
Speziell trainiert für Python, JavaScript und TypeScript. Kontext: 128k Token Kontext. |
✓ |
Juli 2025 |
Perplexity#
Die Perplexity-Modelle kombinieren Suchmaschine und Sprachmodell. Sie eignen sich hervorragend für Recherchen. Abgerechnet wird nach Token und Suchen. Bei einem Aufruf können eine oder mehrere Suchen durchgeführt werden.
Bemerkung
Perplexity-Modelle können keine Tools verwenden.
Modell |
Beschreibung |
Vision |
Tools |
Denken |
Wissen |
|---|---|---|---|---|---|
Sonar Reasoning pro (Recherche) |
Reasoning-Modell mit Internetsuche. Denkt zuerst über die Aufgabe nach, dann wird gesucht. |
✓ |
|||
Sonar Deep Research (Tiefenrecherche) |
Für aufwendige Recherchen. Je nach Aufgabenstellung kann das Modell 5-10 Minuten unterwegs sein. |
✓ |
|||
Sonar |
Kleine und schnellere Version von Sonar mit Internetsuche. 128k Token Kontext. |
Lege dir bei einem oder mehreren dieser KI-Provider einen Account an und übermittele die API-Keys an das Radio Creator Team.
Open Source-Modelle#
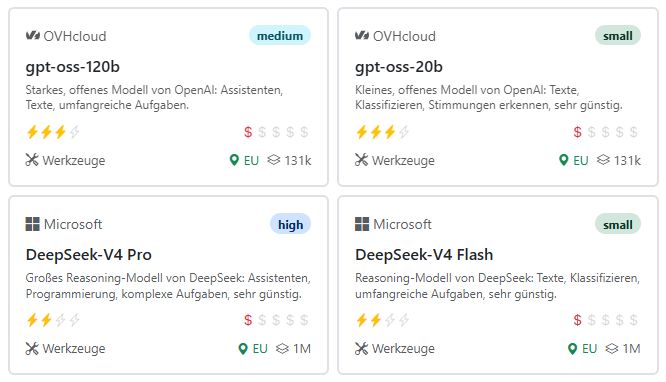
Einige Hoster in Europa bieten auch Open Source-Modelle an. Diese haben zwei Vorteile:
Standort in Europa: Die Daten werden nicht in die USA oder andere Regionen übertragen, sondern bleiben in der EU. Das ist besonders wichtig, wenn die Richtlinien deiner Organisation es erfordern, dass die Daten nur in der EU verarbeitet werden dürfen.
Kosten: Open Source-Modelle sind in der Regel deutlich günstiger als kommerzielle Modelle.
Wir arbeiten zurzeit mit OVHcloud in Frankreich zusammen, um die Open Source-Modelle GPT-OSS und Qwen in den AI-Tools verfügbar zu machen.
Microsoft Foundry und Fireworks AI bieten ebenfalls Open Source-Modelle an und verwenden dafür ihre weltweite Server-Infrastruktur. So ist es möglich, chinesische Modelle wie DeepSeek, Kimi oder GLM zu nutzen, ohne auf die Server der chinesischen Anbieter zugreifen zu müssen.
Open Source Modelle hinken kommerziellen Modellen in der Leistungsfähigkeit meist einige Monate hinterher, aber sie können für viele Aufgaben eine gute und kostengünstige Alternative sein.
Nachdenken#

Die meisten KI-Modelle der neueren Generation verfügen über erweitertes Nachdenken (Reasoning). Natürlich denken KI-Modelle nicht wirklich, sondern sie simulieren das Nachdenken, indem sie intern mehrere Schritte durchlaufen, bevor sie eine Antwort generieren. Das ermöglicht es ihnen, komplexe Aufgaben besser zu bewältigen, logische Schlussfolgerungen zu ziehen und Informationen aus verschiedenen Quellen zu kombinieren.
Das dauert natürlich länger und verbraucht mehr Tokens. Du musst für dich abwägen, ob die höheren Kosten und die längere Wartezeit den Vorteil der besseren Antworten wert sind.
Nachdenken steuern#
Manchmal ist es sinnvoll, das Gedanken-Budget zu steuern. Zum Beispiel in einem Arbeitsablauf, der aus mehreren Teil-Schritten besteht. Du möchtest ein starkes Modell verwenden, aber verhindern, dass durch zu langes Nachdenken viele Tokens verbraucht werden.
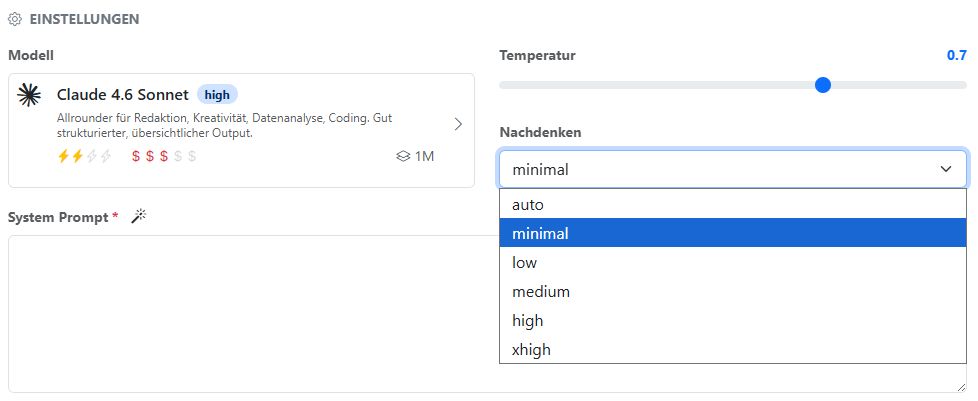
In den Einstellungen für Assistenten und Arbeitsabläufe findest du bei der Modell-Auswahl und Temperatur-Einstellung das Drop Down Menü Nachdenken. Du hast die Auswahl zwischen minimal (Denken ausgeschaltet), low, medium, high, xhigh und auto.
Nicht alle Modelle können das. Bei Modellen, die das Gedanken-Budget nicht unterstützen, wird diese Auswahl nicht angezeigt.
Falls du nicht sicher bist, wähle am besten auto. Dann entscheidet das Modell selbst, wie viel Gedanken-Budget es für die Aufgabe benötigt.
Compliance & Datenschutz#
Die Server auf denen die AI-Tools gehostet werden, stehen in Limburg in Hessen (Deutschland). Für alle KI-Aufgaben werden deine Prompts und die Antworten an die Server der jeweiligen KI-Anbieter in der EU oder den USA gesendet. Das geschieht über eine Software-Schnittstelle (API) und die Daten werden nicht zum Training der Modelle verwendet.
Falls die Richtlinien deiner Organisation es erfordern, dass die Daten nur in der EU verarbeitet werden, kannst du die KI-Modelle von Microsoft Foundry, Mistral AI und OVHcloud nutzen.
Accounts erstellen#
Für den Betrieb der AI-Tools sind API-Keys bei den verschiedenen KI-Anbietern erforderlich. Wenn du Gemini von Google, Mistral, Anthropic, OpenAI oder Perplexity nutzen möchtest, musst du einen Account bei diesen Anbietern erstellen. Dein Token-Verbrauch wird dann über diese Accounts abgerechnet.
Du kannst Sprachmodelle aber auch ohne eigenen Account nutzen. Wir richten dann alles für dich ein und die Abrechnung erfolgt über dein Token-Guthaben.
OpenAI Account#
Für die KI-Modelle von OpenAI (ChatGPT) gibt es zwei Möglichkeiten: Du nutzt sie direkt bei OpenAI in den USA oder über Microsoft Azure in Europa (Schweden). Die Anleitung für Microsoft Azure OpenAI findest du weiter unten.
Eröffne zunächst ein kostenloses Konto bei OpenAI: https://platform.openai.com/signup
Erstelle dann auf der OpenAI-Plattform den API-Key für die AI-Tools und übermittele ihn an das Radio Creator Team. Der Key hat dieses Format: sk-1234567890abcdef1234567890abcdef
Account für GPT Image verifizieren#
Um den Bildgenerator GPT Image nutzen zu können, muss der Account einmalig verifiziert werden. Das geht ganz einfach über diesen Link, der zu den Einstellungen in deinem OpenAI-Account führt:
https://platform.openai.com/settings/organization/general
Klicke auf „Verify Organization“. Danach kann es bis zu 15 Minuten dauern, bis GPT Image freigegeben wird.
Microsoft Foundry (Azure OpenAI)#
Die Einrichtung von Sprachmodellen bei Microsoft ist leider etwas umständlich. Dafür gibt es im Foundry-Portal sehr viele Modelle, die zum großen Teil in Europa (Schweden) gehostet werden. Dein Administrator kann dir helfen und wenn es Probleme gibt, wende dich an das Radio Creator Team.
Zunächst ist ein Microsoft Azure-Konto erforderlich. Dort muss eine neue Ressource erstellt werden: https://learn.microsoft.com/de-de/azure/foundry/tutorials/quickstart-create-foundry-resources?tabs=azurecli
Anschließend kannst du im Foundry-Portal KI-Modelle auswählen und bereitstellen: https://learn.microsoft.com/de-de/azure/foundry/foundry-models/how-to/deploy-foundry-models
Bitte unbedingt die Region Europe/Schweden Central auswählen, damit die Datenverarbeitung in der EU erfolgt.
Nachdem die Modelle bereitgestellt sind, müssen sie noch für die AI-Tools freigegeben werden. Das Radio Creator Team richtet das für dich ein. Bitte übermittle dazu die Namen der bereitgestellten Modelle und den API-Key.
Außerdem auch den API-Endpunkt. Den findest du in der Übersicht der bereitgestellten Modelle im Foundry-Portal. Er hat dieses Format: https://RESSOURCENAME.openai.azure.com/openai/v1/
Anthropic Account#
Ehemalige Mitarbeiter von OpenAI haben im US-Bundesstaat Delaware die Firma Anthropic gegründet. Sie haben die Claude-Modelle entwickelt. Die Leistungsfähigkeit ist mit der von OpenAI vergleichbar.
Anthropic-Konto erstellen: https://console.anthropic.com/
In der Konsole unter API keys einen Key erstellen und an das Radio Creator Team übermitteln. Der Key hat dieses Format: sk-ant-api12-3456…
Google Account#
Die Gemini-Modelle von Google zählen zu den derzeit leistungsfähigsten LLMs. Sie können die Google KI-Suche nutzen, um Informationen aus dem Internet zu erhalten.
Um Gemini und die Google KI-Suche nutzen zu können, ist ein API-Schlüssel erforderlich. Hier geht es zur Anleitung: https://ai.google.dev/gemini-api/docs/api-key?hl=de
API-Key in Google AI Studio erstellen: https://aistudio.google.com/app/apikey
WICHTIG: Verwende unbedingt den kostenpflichtigen Tarif. Nur dann werden deine Daten nicht für Trainingszwecke verwendet. Im Google AI Studio kannst du bei jedem API-Schlüssel den Tarif auswählen.
Mistral Account#
Bei großen Sprachmodellen (LLM) ist Mistral AI in Europa führend. Die Gründer waren zuvor Forscher bei Meta und Google. Neben Open Source-Modellen wie Mistral Small bietet Mistral auch kommerzielle Modelle an.
Codestral ist ein Modell, das speziell für Programmieraufgaben trainiert wurde. Es kann 256k Token verarbeiten. Das große Reasoning-Modell Mistral Large ist für komplexe Aufgaben geeignet. Die Leistungsfähigkeit beim „Nachdenken“ und nutzen von Tools liegt etwas unter Anthropic und OpenAI.
Ein großer Vorteil von Mistral AI ist, dass die Server in Europa stehen. Die Datenverarbeitung erfolgt in der EU.
Mistral-Konto erstellen: https://console.mistral.ai/
In der Konsole unter API-Schlüssel einen Key erstellen und an das Radio Creator Team übermitteln.
Perplexity Account#
Das Startup aus San Francisco kombiniert ein Sprachmodell mit einer Suchmaschine. Perplexity verwendet dazu einen eigenen Crawler, den Perplexitybot, der regelmäßig das Internet durchsucht.
Die Sprachmodelle haben Reasoning-Fähigkeiten, überlegen also zuerst, wie sie eine Aufgabe angehen. Perplexity ist damit hervorragend für Recherchen geeignet.
Am weitesten geht dabei das Modell Sonar Deep Research. Es kann umfangreiche Recherchen durchführen und benötigt dafür 5-10 Minuten.
Abgerechnet wird nach Token und Suchen. Pro Aufgabe können eine oder mehrere Suchen ausgeführt werden.
Perplexity-Konto erstellen: https://docs.perplexity.ai/guides/getting-started
AssemblyAI Account#
AssemblyAI bietet KI-Modelle für die Transkription von Audiodateien an. Diese Modelle werden zum Beispiel für die Transkription in den AI-Tools verwendet.
Für das automatische Schneiden in den AI-Tools ist die KI von AssemblyAI ebenfalls erforderlich. Sie liefert besonders genaue Zeitstempel für die Schnitte und kann wortwörtlich transkribieren.
Konto bei AssemblyAI erstellen: https://www.assemblyai.com/dashboard/signup
Kosten und Guthaben#
Während du die AI-Tools verwendest, fallen Kosten bei verschiedenen Anbietern an. Die KI-Nutzung wird üblicherweise in Tokens gemessen. Ein Token entspricht etwa 4 Zeichen Text oder 0,75 Wörtern.
Unterschieden wird nach Eingabe-Tokens (die Prompts, die du eingibst) und Ausgabe-Tokens (die Antworten der KI).
Bei einzelnen Modellen gibt es noch so genannte Reasoning-Tokens. Diese werden verwendet, wenn die KI „nachdenkt“. Oder Citation-Tokens, um Quellen zu zitieren.
Außerdem werden Werkzeuge, wie die Google KI-Suche oder Google-Maps berechnet.
Und bei jedem Sprachmodell sind die Kosten, je nach Leistungsfähigkeit, unterschiedlich hoch:
Anthropic: https://platform.claude.com/docs/en/about-claude/pricing
Google Gemini: https://ai.google.dev/gemini-api/docs/pricing?hl=de
Mistral-Modelle: https://mistral.ai/pricing/#api
Perplexity: https://docs.perplexity.ai/getting-started/pricing
AssemblyAI: https://www.assemblyai.com/pricing
Microsoft Foundry: https://azure.microsoft.com/en-us/pricing/details/ai-foundry-models/deepseek/
OVHcloud: https://www.ovhcloud.com/en-gb/public-cloud/ai-endpoints/catalog/
Verbrauch anzeigen#
Du kannst dir jederzeit den aktuellen Verbrauch der KI-Modelle in den AI-Tools anzeigen lassen. Klicke dazu auf das drei Punkte-Menü bei der Chat-Eingabe und wähle Verbrauch anzeigen.
Am linken Rand siehst du dann die Anzahl der verbrauchten Tokens und die Kosten in Euro. Auf Mobilgeräten sind die Kosten-Pills über dem Chat-Fenster.
Ab einem bestimmten Verbrauch erscheinen die Kosten-Pills automatisch, damit du den Überblick behältst.
Aktueller Chat#
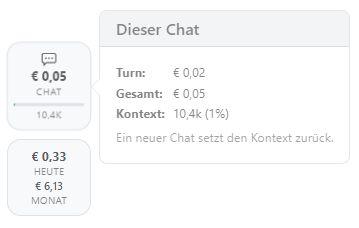
Die Kosten die der aktuelle Chat bisher verursacht hat, werden in der Chat-Pill angezeigt. Klicke darauf und du siehst mehr Details:
Turn: Kosten für das letzte Prompt, das du abgeschickt hast.
Gesamt: Kosten für den gesamten Chat, also alle bisherigen Prompts und Antworten.
Kontext: Anzahl der Tokens, die sich aktuell im Chat befinden und immer wieder zur KI geschickt werden. Der Prozentwert zeigt an, wie weit das Kontext-Fenster des Modells schon gefüllt ist. Je voller das Kontext-Fenster, desto langsamer wird die KI und desto ungenauer die Antworten.
Tipp
Wenn du einen langen Chat hast, starte lieber einen neuen Chat. Wenn du den Kontext aus einem vorherigen Chat benötigst, lass dir vom Assistenten die wichtigsten Informationen zusammenfassen und kopiere sie in einen neuen Chat.
Aktuelle Kosten#
In der Kosten-Pill siehst du die Kosten, die mit deiner KI-Nutzung heute und im aktuellen Monat entstanden sind.
Die beiden Anzeigen helfen dir, deine Prompts und Assistenten zu verbessern.
Sprachmodelle mit Guthaben nutzen#
Falls deine Organisation keinen eigenen Account bei einem KI-Anbieter hat, kannst du die Sprachmodelle dennoch nutzen. Wir richten diese Modelle für dich ein und die Abrechnung erfolgt über dein Token-Guthaben.
Ein Beispiel: Deine Organisation hat keinen eigenen Account bei Google. Du kannst trotzdem die Google-KI-Suche und Google Maps für die Recherche verwenden. Die Abrechnung dafür erfolgt über das Token-Guthaben.
Wir berechnen die Preise nach den offiziellen Tarifen der Anbieter und erheben für die Verwaltung eine Service-Gebühr von 20 Prozent. Mehr zu Guthaben und Abrechnung erfährst du im Abschnitt Guthaben und Abrechnung.